
Using Deep Sea Animal Recognition to Measure the Impact of Offshore Wind Energy
Overview
In November 2017, California Polytechnic State University (Cal Poly) received a $200,000 grant from the California Energy Commission to build a proof of concept that leveraged image recognition and machine learning to automatically annotate and classify deep sea organisms documented on video by the Monterey Bay Aquarium Research Institute (MBARI). The objective of the proof of concept was to help researchers assess potential impacts to the deep-water ocean ecosystem associated with implementing offshore wind energy technologies.
Problem
Currently, marine scientists must manually identify and collect deep-water ocean species data from thousands of hours of videos recorded by a rover to create accurate datasets that reveal species distribution and abundance. This process is costly, but the data generated is imperative to providing a baseline for pre and post installation assessments of species counts to determine the long-term effect of offshore wind energy development.

Figure 1: Offshore Wind Energy Technology
Results
A project team was formed, which included Cal Poly’s Digital Transformation Hub (DxHub), five computer science students, four marine biology students, two faculty and one staff member at Cal Poly. Over a 10-month period, the team, with advisement from MBARI professional video annotators and engineers, created an annotation tool that would feed streaming video into a web browser to be annotated by scientists. The application allows scientists to easily drag multiple bounding boxes onto a screen and then select which species is represented on the screen. These images are then used as training data for a Machine Learning (ML) model that will attempt to detect and classify which species are present in future videos. To further amplify images created by this process, the team added in the ability to track an organism for the duration it is on the screen from a single annotation. This can create an extra 30-100 images per annotation by a scientist, creating a large number of images to train the ML model in a short amount of time while saving valuable time for the scientists in the annotation process.
Throughout the course of this project, annotators have been able to create 20,000 labeled images in total with many species having over 5,000 labeled images individually. With these labeled images, optimizing the ML model and using humans to further tune the model through Human-in-the-loop training, the project team anticipates being able to create a model that will be able to identify species with 90% accuracy.
Solutions Architecture Options and Scenarios
The project team used several technology services from Amazon Web Services (AWS) in conjunction with code written to create the application. For the annotation application website, the developers used AWS Elastic Beanstalk to write and upload code into a cloud environment. Elastic Beanstalk handled the provisioning of the environment and all of the components needed to run and scale the application. This allowed the project team to focus on developing the application without having to know or understand the underlying AWS services. Elastic Beanstalk created Amazon EC2 instances to run the Node.JS code, and an Elastic Load Balancer for high availability. Amazon RDS running PostgreSQL was used to store label and training information created in the application, and Amazon S3 was used to store images and raw video.
For the Machine Learning (ML) portion of the application, the students tried different ML algorithms and decided on ResNet50 RetinaNet in Keras to perform object detection. To train the model, a very large Amazon EC2 G3 Instance with access to high performance GPUs was used to handle the high-resolution images pulled from the video.
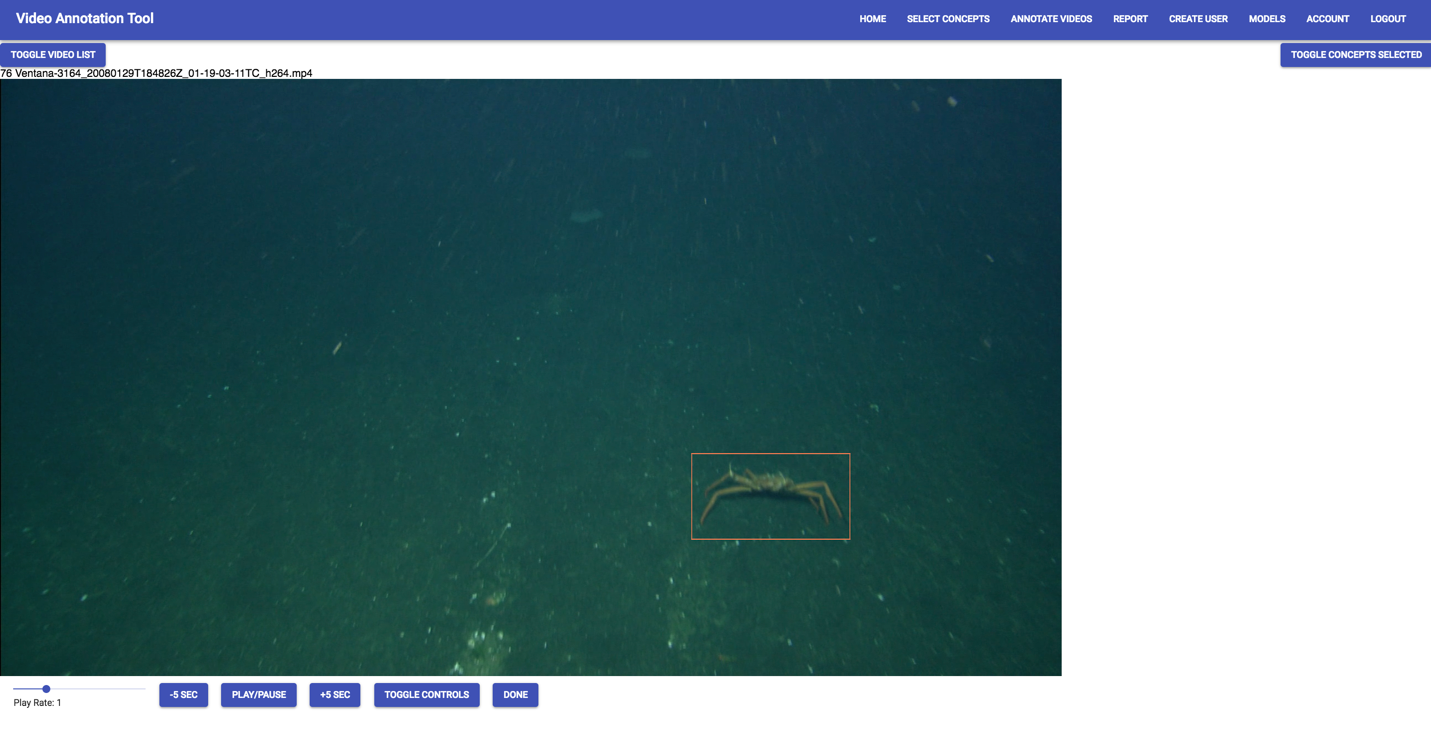
Figure 2: Screenshot from the annotation application
Conclusion
This project is still ongoing. Updates will be posted to this blog as the project progresses.
About the DxHub
The Cal Poly Digital Transformation Hub (DxHub) is a strategic relationship with Amazon Web Services (AWS) and is the world’s first cloud innovation center supported by AWS on a University campus. The primary goal of the DxHub is to provide real-world problem-solving experiences to students by immersing them in the application of proven innovation methods in combination with the latest technologies to solve important challenges in the public sector. The challenges being addressed cover a wide variety of topics including homelessness, evidence-based policing, digital literacy, virtual cybersecurity laboratories and many others. The DxHub leverages the deep subject matter expertise of government, education and non-profit organizations to clearly understand the customers affected by public sector challenges and develops solutions that meet the customer needs.