
Transforming public health surveillance: AI-powered semantic interoperability for electronic case reports
Overview
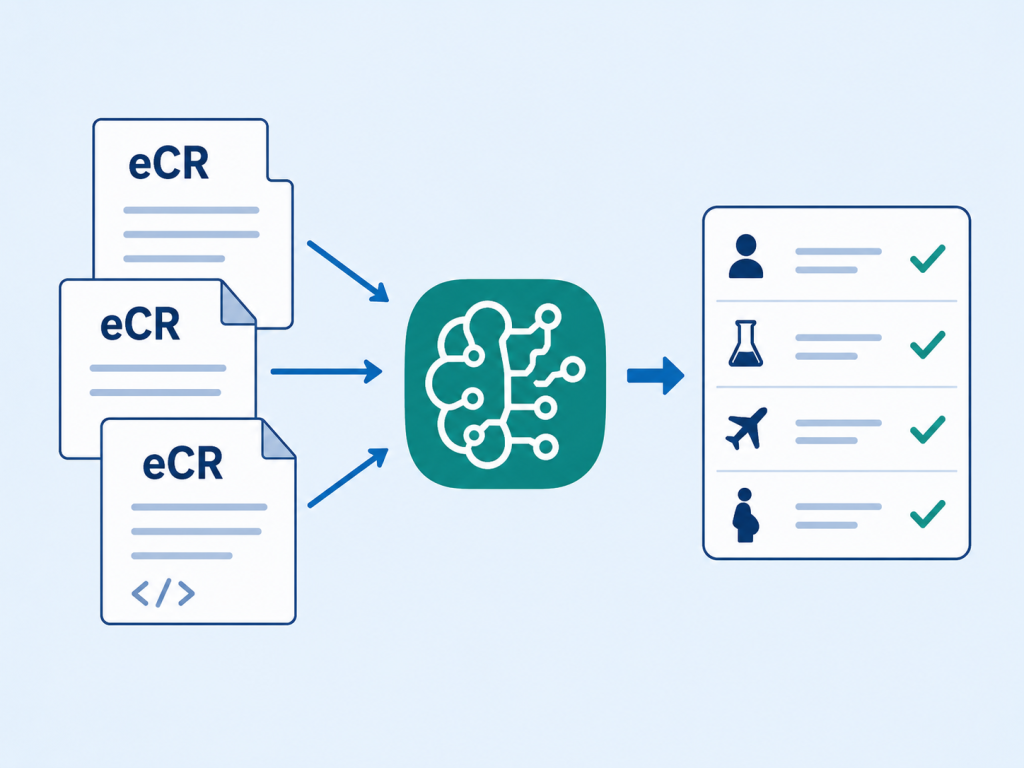
The Digital Transformation Hub (DxHub) at California Polytechnic State University (Cal Poly) in San Luis Obispo – powered by Amazon Web Services (AWS) and part of the AWS Cloud Innovation Centers (CIC) program to develop an innovative AI-powered pipeline that transforms how public health agencies process electronic case reports (eCRs). When a patient visits a doctor, or is admitted to a hospital, if the patient has a reportable disease, an eCR may be generated as an XML document containing important clinical information for public health agencies. These reports are vital for public health surveillance, helping agencies track disease outbreaks, monitor health trends, and respond to emerging threats. However, much of the most valuable information is buried in unstructured, free-form clinical text that has traditionally been nearly impossible to extract at scale. This new solution uses generative AI to read, understand, classify, and extract meaningful information from eCR documents, turning messy clinical narratives into structured, actionable data.
Problem
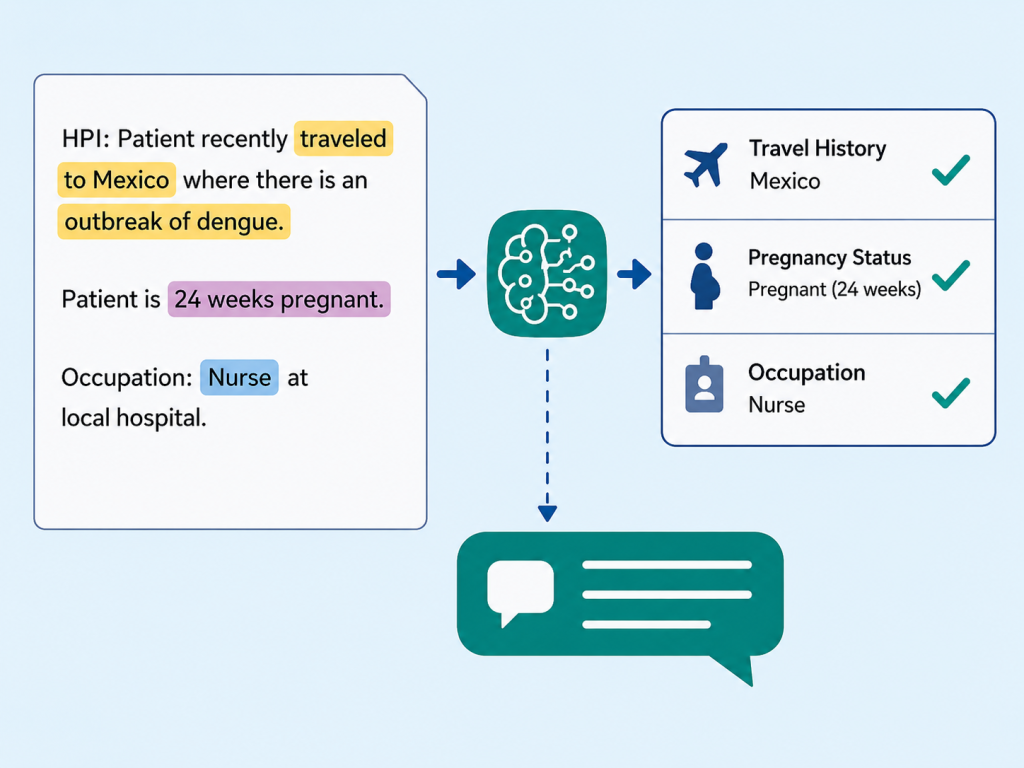
Public health agencies like SNHD receive hundreds or thousands of eCR documents, each containing potentially life-saving surveillance information locked away in free-form narrative text. A nurse’s note might mention that a patient recently traveled to a region experiencing a disease outbreak, that a patient is pregnant, or that a patient’s occupation puts them at elevated risk for certain conditions — details that are essential for public health decision-making but extraordinarily difficult to surface using traditional methods. Manually reading through eCR documents to find these critical details is time-consuming, error-prone, and simply doesn’t scale to the volume of reports generated daily across the healthcare system. Compounding the challenge, eCR documents are riddled with internal cross-references — XML tags that point to data defined elsewhere in the document rather than containing the data inline. Before any meaningful analysis can occur, these references must be resolved and the documents normalized, a tedious preprocessing step that has historically been a significant barrier for health agencies trying to derive insights from their eCR data. The result is that vital public health signals — like a cluster of pregnant patients, patients exposed to an infectious disease, or an emerging pattern of travel-related cases — can be delayed or missed entirely, hampering the ability of public health agencies to respond quickly to developing health threats.

Innovation In Action
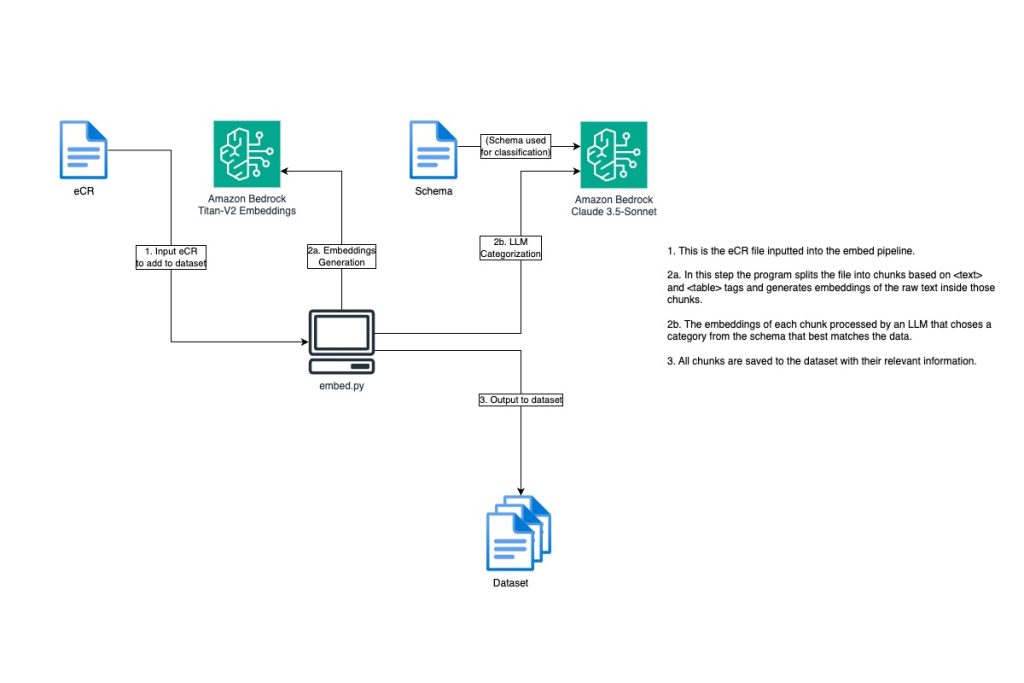
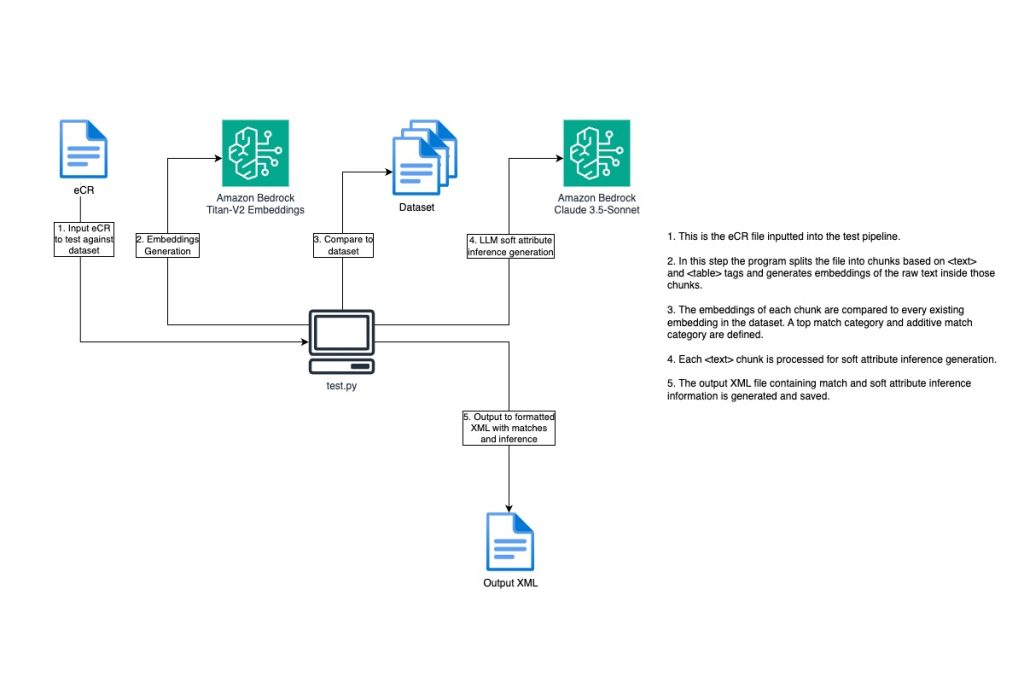
The eCR Semantic Interoperability pipeline was originally designed to operate in two main phases that together deliver structured, annotated clinical intelligence. In Phase 1, users feed known, labeled eCR documents into the system to build a reference dataset. The pipeline preprocesses the raw eCR XML — resolving internal cross-references and cleaning up namespaces — then splits each document into logical sections and generates vector embeddings, mathematical representations of each section’s meaning. These embeddings are categorized against a customizable schema with categories like “Patient Encounter,” “Lab Results,” “Pregnancy Status,” or “Travel History,” and stored locally for future comparison. In Phase 2, when a new, unseen eCR is submitted, the system processes it the same way and compares each section’s embedding against the reference dataset using similarity matching. Each section receives a primary category match along with additive scores across secondary categories, providing a nuanced view of its content. A large language model then reads the free-form text to extract specific “soft attributes” — such as pregnancy status, recent travel history, and occupation — complete with chain-of-thought reasoning explaining how it reached each conclusion. As the engagement with SNHD progressed, a compelling insight emerged: while the full embedding and classification pipeline offered powerful capabilities, SNHD’s most pressing need was actually solved by the preprocessing stage alone. Their downstream systems and analysts could work effectively with eCR data once the internal XML references were resolved — meaning every tag was replaced with the actual data it pointed to, producing a flat, self-contained document. SNHD transitioned their production use case to leverage just this preprocessing functionality, unlocking immediate value without requiring the full AI classification workflow. This pivot highlighted a key strength of the pipeline’s modular design: organizations can adopt only the components that match their maturity and needs, whether that’s lightweight XML resolution, extraction-only tagging, or the full semantic classification experience.
Technical Solution
The solution is a Python-based pipeline that runs on AWS services or on premise and is designed for simplicity and flexibility — it can run locally or on an Amazon Elastic Compute Cloud (Amazon EC2) or AWS Lambda instance with no complex infrastructure required. Amazon Bedrock provides the AI backbone, with Amazon Titan Embeddings V2 generating the vector representations of document sections and Anthropic’s Claude Haiku 4.5 (or optionally any modern, capable large language model) or other LLMs handling the natural language inference and soft attribute extraction. Models are configurable via environment variables, enabling organizations to easily experiment with different foundation models as their needs evolve. for standalone XML cleanup and replacing tags with their associated actual values. Shared logic lives in bedrock.py for model interaction and vectoring.py for embedding and categorization. Classification categories are defined in a JSON schema file (hl7_schema.json), making it straightforward to adapt the system to different document types or organizational needs.
Next Steps
The eCR Semantic Interoperability pipeline is designed for iterative improvement. The recommended workflow includes building a “golden template” of validated results, measuring classification accuracy, and refining both the reference dataset and LLM prompts over time — making it a tool that gets better the more an organization uses it. SNHD’s adoption of the standalone preprocessing capability demonstrates how the pipeline can deliver tangible value at multiple levels of engagement, and the DxHub team will continue to partner with SNHD as their use case evolves — with the full classification and soft attribute extraction capabilities available whenever they are ready to expand. The practical impact for public health agencies, healthcare organizations, and epidemiological teams is significant: faster identification of pregnant patients exposed to infectious diseases, quicker detection of travel-related outbreak patterns, and more complete occupational health data — all extracted automatically from documents that previously required line-by-line human review. Looking ahead, the flexible schema and prompt architecture means the solution has broad applicability beyond the initial eCR use case, with potential to extend to other clinical document types and public health data interfaces. Organizations interested in learning more about the eCR Semantic Interoperability pipeline or engaging with the Cal Poly Digital Transformation Hub can reach out to Nick Osterbur (nosterb@amazon.com) or visit the DxHub website.



Supporting Documents
| Source Code | All of the code and assets developed during the course of creating the prototype. |
| A diagram that describes the technical components needed to implement the solution. |
{kind=link}
{kind=link}
About the DxHub
The Cal Poly Digital Transformation Hub (DxHub) is a strategic relationship with Amazon Web Services (AWS) and is the world’s first cloud innovation center supported by AWS on a University campus. The primary goal of the DxHub is to provide students with real-world problem-solving experiences by immersing them in the application of proven innovation methods in combination with the latest technologies to solve important challenges in the public sector. The challenges being addressed cover a wide variety of topics including homelessness, evidence-based policing, digital literacy, virtual cybersecurity laboratories and many others. The DxHub leverages the deep subject matter expertise of government, education, and non-profit organizations to clearly understand the customers affected by public sector challenges and develop solutions that meet the customer needs.